If you regularly read cognitive science or psychology blogs (or even just the lowly New York Times!), you’ve probably heard of something called the Dunning-Kruger effect. The Dunning-Kruger effect refers to the seemingly pervasive tendency of poor performers to overestimate their abilities relative to other people–and, to a lesser extent, for high performers to underestimate their abilities. The explanation for this, according to Kruger and Dunning, who first reported the effect in an extremely influential 1999 article in the Journal of Personality and Social Psychology, is that incompetent people by lack the skills they’d need in order to be able to distinguish good performers from bad performers:
…people who lack the knowledge or wisdom to perform well are often unaware of this fact. We attribute this lack of awareness to a deficit in metacognitive skill. That is, the same incompetence that leads them to make wrong choices also deprives them of the savvy necessary to recognize competence, be it their own or anyone else’s.
For reasons I’m not really clear on, the Dunning-Kruger effect seems to be experiencing something of a renaissance over the past few months; it’s everywhere in the blogosphere and media. For instance, here are just a few alleged Dunning-Krugerisms from the past few weeks:
…So what does this mean in business? Well, it’s all over the place. Even the title of Dunning and Kruger’s paper, the part about inflated self-assessments, reminds me of a truism that was pointed out by a supervisor early in my career: The best employees will invariably be the hardest on themselves in self-evaluations, while the lowest performers can be counted on to think they are doing excellent work…
…Heidi Montag and Spencer Pratt are great examples of the Dunning-Kruger effect. A whole industry of assholes are making a living off of encouraging two attractive yet untalented people they are actually genius auteurs. The bubble around them is so thick, they may never escape it. At this point, all of America (at least those who know who they are), is in on the joke ““ yet the two people in the center of this tragedy are completely unaware…
…Not so fast there — the Dunning-Kruger effect comes into play here. People in the United States do not have a high level of understanding of evolution, and this survey did not measure actual competence. I’ve found that the people most likely to declare that they have a thorough knowledge of evolution are the creationists“¦but that a brief conversation is always sufficient to discover that all they’ve really got is a confused welter of misinformation…
As you can see, the findings reported by Kruger and Dunning are often interpreted to suggest that the less competent people are, the more competent they think they are. People who perform worst at a task tend to think they’re god’s gift to said task, and the people who can actually do said task often display excessive modesty. I suspect we find this sort of explanation compelling because it appeals to our implicit just-world theories: we’d like to believe that people who obnoxiously proclaim their excellence at X, Y, and Z must really not be so very good at X, Y, and Z at all, and must be (over)compensating for some actual deficiency; it’s much less pleasant to imagine that people who go around shoving their (alleged) superiority in our faces might really be better than us at what they do.
Unfortunately, Kruger and Dunning never actually provided any support for this type of just-world view; their studies categorically didn’t show that incompetent people are more confident or arrogant than competent people. What they did show is this:
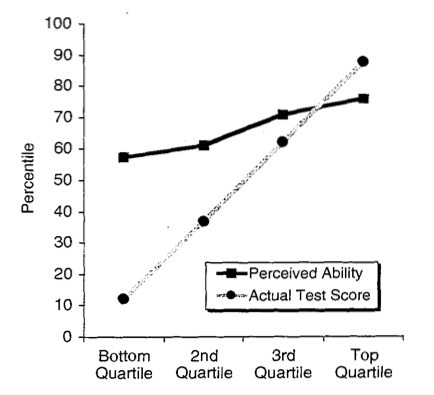
This is one of the key figures from Kruger and Dunning’s 1999 paper (and the basic effect has been replicated many times since). The critical point to note is that there’s a clear positive correlation between actual performance (gray line) and perceived performance (black line): the people in the top quartile for actual performance think they perform better than the people in the second quartile, who in turn think they perform better than the people in the third quartile, and so on. So the bias is definitively not that incompetent people think they’re better than competent people. Rather, it’s that incompetent people think they’re much better than they actually are. But they typically still don’t think they’re quite as good as people who, you know, actually are good. (It’s important to note that Dunning and Kruger never claimed to show that the unskilled think they’re better than the skilled; that’s just the way the finding is often interpreted by others.)
That said, it’s clear that there is a very large discrepancy between the way incompetent people actually perform and the way they perceive their own performance level, whereas the discrepancy is much smaller for highly competent individuals. So the big question is why. Kruger and Dunning’s explanation, as I mentioned above, is that incompetent people lack the skills they’d need in order to know they’re incompetent. For example, if you’re not very good at learning languages, it might be hard for you to tell that you’re not very good, because the very skills that you’d need in order to distinguish someone who’s good from someone who’s not are the ones you lack. If you can’t hear the distinction between two different phonemes, how could you ever know who has native-like pronunciation ability and who doesn’t? If you don’t understand very many words in another language, how can you evaluate the size of your own vocabulary in relation to other people’s?
This appeal to people’s meta-cognitive abilities (i.e., their knowledge about their knowledge) has some intuitive plausibility, and Kruger, Dunning and their colleagues have provided quite a bit of evidence for it over the past decade. That said, it’s by no means the only explanation around; over the past few years, a fairly sizeable literature criticizing or extending Kruger and Dunning’s work has developed. I’ll mention just three plausible (and mutually compatible) alternative accounts people have proposed (but there are others!)
1. Regression toward the mean. Probably the most common criticism of the Dunning-Kruger effect is that it simply reflects regression to the mean–that is, it’s a statistical artifact. Regression to the mean refers to the fact that any time you select a group of individuals based on some criterion, and then measure the standing of those individuals on some other dimension, performance levels will tend to shift (or regress) toward the mean level. It’s a notoriously underappreciated problem, and probably explains many, many phenomena that people have tried to interpret substantively. For instance, in placebo-controlled clinical trials of SSRIs, depressed people tend to get better in both the drug and placebo conditions. Some of this is undoubtedly due to the placebo effect, but much of it is probably also due to what’s often referred to as “natural history”. Depression, like most things, tends to be cyclical: people get better or worse better over time, often for no apparent rhyme or reason. But since people tend to seek help (and sign up for drug trials) primarily when they’re doing particularly badly, it follows that most people would get better to some extent even without any treatment. That’s regression to the mean (the Wikipedia entry has other nice examples–for example, the famous Sports Illustrated Cover Jinx).
In the context of the Dunning-Kruger effect, the argument is that incompetent people simply regress toward the mean when you ask them to evaluate their own performance. Since perceived performance is influenced not only by actual performance, but also by many other factors (e.g., one’s personality, meta-cognitive ability, measurement error, etc.), it follows that, on average, people with extreme levels of actual performance won’t be quite as extreme in terms of their perception of their performance. So, much of the Dunning-Kruger effect arguably doesn’t need to be explained at all, and in fact, it would be quite surprising if you didn’t see a pattern of results that looks at least somewhat like the figure above.
2. Regression to the mean plus better-than-average. Having said that, it’s clear that regression to the mean can’t explain everything about the Dunning-Kruger effect. One problem is that it doesn’t explain why the effect is greater at the low end than at the high end. That is, incompetent people tend to overestimate their performance to a much greater extent than competent people underestimate their performance. This asymmetry can’t be explained solely by regression to the mean. It can, however, be explained by a combination of RTM and a “better-than-average” (or self-enhancement) heuristic which says that, in general, most people have a tendency to view themselves excessively positively. This two-pronged explanation was proposed by Krueger and Mueller in a 2002 study (note that Krueger and Kruger are different people!), who argued that poor performers suffer from a double whammy: not only do their perceptions of their own performance regress toward the mean, but those perceptions are also further inflated by the self-enhancement bias. In contrast, for high performers, these two effects largely balance each other out: regression to the mean causes high performers to underestimate their performance, but to some extent that underestimation is offset by the self-enhancement bias. As a result, it looks as though high performers make more accurate judgments than low performers, when in reality the high performers are just lucky to be where they are in the distribution.
3. The instrumental role of task difficulty. Consistent with the notion that the Dunning-Kruger effect is at least partly a statistical artifact, some studies have shown that the asymmetry reported by Kruger and Dunning (i.e., the smaller discrepancy for high performers than for low performers) actually goes away, and even reverses, when the ability tests given to participants are very difficult. For instance, Burson and colleagues (2006), writing in JPSP, showed that when University of Chicago undergraduates were asked moderately difficult trivia questions about their university, the subjects who performed best were just as poorly calibrated as the people who performed worst, in the sense that their estimates of how well they did relative to other people were wildly inaccurate. Here’s what that looks like:

Notice that this finding wasn’t anomalous with respect to the Kruger and Dunning findings; when participants were given easier trivia (the diamond-studded line), Burson et al observed the standard pattern, with poor performers seemingly showing worse calibration. Simply knocking about 10% off the accuracy rate on the trivia questions was enough to induce a large shift in the relative mismatch between perceptions of ability and actual ability. Burson et al then went on to replicate this pattern in two additional studies involving a number of different judgments and tasks, so this result isn’t specific to trivia questions. In fact, in the later studies, Burson et al showed that when the task was really difficult, poor performers were actually considerably better calibrated than high performers.
Looking at the figure above, it’s not hard to see why this would be. Since the slope of the line tends to be pretty constant in these types of experiments, any change in mean performance levels (i.e., a shift in intercept on the y-axis) will necessarily result in a larger difference between actual and perceived performance at the high end. Conversely, if you raise the line, you maximize the difference between actual and perceived performance at the lower end.
To get an intuitive sense of what’s happening here, just think of it this way: if you’re performing a very difficult task, you’re probably going to find the experience subjectively demanding even if you’re at the high end relative to other people. Since people’s judgments about their own relative standing depends to a substantial extent on their subjective perception of their own performance (i.e., you use your sense of how easy a task was as a proxy of how good you must be at it), high performers are going to end up systematically underestimating how well they did. When a task is difficult, most people assume they must have done relatively poorly compared to other people. Conversely, when a task is relatively easy (and the tasks Dunning and Kruger studied were on the easier side), most people assume they must be pretty good compared to others. As a result, it’s going to look like the people who perform well are well-calibrated when the task is easy and poorly-calibrated when the task is difficult; less competent people are going to show exactly the opposite pattern. And note that this doesn’t require us to assume any relationship between actual performance and perceived performance. You would expect to get the Dunning-Kruger effect for easy tasks even if there was exactly zero correlation between how good people actually are at something and how good they think they are.
Here’s how Burson et al summarized their findings:
Our studies replicate, eliminate, or reverse the association between task performance and judgment accuracy reported by Kruger and Dunning (1999) as a function of task difficulty. On easy tasks, where there is a positive bias, the best performers are also the most accurate in estimating their standing, but on difficult tasks, where there is a negative bias, the worst performers are the most accurate. This pattern is consistent with a combination of noisy estimates and overall bias, with no need to invoke differences in metacognitive abilities. In this regard, our findings support Krueger and Mueller’s (2002) reinterpretation of Kruger and Dunning’s (1999) findings. An association between task-related skills and metacognitive insight may indeed exist, and later we offer some suggestions for ways to test for it. However, our analyses indicate that the primary drivers of errors in judging relative standing are general inaccuracy and overall biases tied to task difficulty. Thus, it is important to know more about those sources of error in order to better understand and ameliorate them.
What should we conclude from these (and other) studies? I think the jury’s still out to some extent, but at minimum, I think it’s clear that much of the Dunning-Kruger effect reflects either statistical artifact (regression to the mean), or much more general cognitive biases (the tendency to self-enhance and/or to use one’s subjective experience as a guide to one’s standing in relation to others). This doesn’t mean that the meta-cognitive explanation preferred by Dunning, Kruger and colleagues can’t hold in some situations; it very well may be that in some cases, and to some extent, people’s lack of skill is really what prevents them from accurately determining their standing in relation to others. But I think our default position should be to prefer the alternative explanations I’ve discussed above, because they’re (a) simpler, (b) more general (they explain lots of other phenomena), and (c) necessary (frankly, it’d be amazing if regression to the mean didn’t explain at least part of the effect!).
We should also try to be aware of another very powerful cognitive bias whenever we use the Dunning-Kruger effect to explain the people or situations around us–namely, confirmation bias. If you believe that incompetent people don’t know enough to know they’re incompetent, it’s not hard to find anecdotal evidence for that; after all, we all know people who are both arrogant and not very good at what they do. But if you stop to look for it, it’s probably also not hard to find disconfirming evidence. After all, there are clearly plenty of people who are good at what they do, but not nearly as good as they think they are (i.e., they’re above average, and still totally miscalibrated in the positive direction). Just like there are plenty of people who are lousy at what they do and recognize their limitations (e.g., I don’t need to be a great runner in order to be able to tell that I’m not a great runner–I’m perfectly well aware that I have terrible endurance, precisely because I can’t finish runs that most other runners find trivial!). But the plural of anecdote is not data, and the data appear to be equivocal. Next time you’re inclined to chalk your obnoxious co-worker’s delusions of grandeur down to the Dunning-Kruger effect, consider the possibility that your co-worker’s simply a jerk–no meta-cognitive incompetence necessary.
![]() Kruger J, & Dunning D (1999). Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77 (6), 1121-34 PMID: 10626367
Kruger J, & Dunning D (1999). Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77 (6), 1121-34 PMID: 10626367
Krueger J, & Mueller RA (2002). Unskilled, unaware, or both? The better-than-average heuristic and statistical regression predict errors in estimates of own performance. Journal of personality and social psychology, 82 (2), 180-8 PMID: 11831408
Burson KA, Larrick RP, & Klayman J (2006). Skilled or unskilled, but still unaware of it: how perceptions of difficulty drive miscalibration in relative comparisons. Journal of personality and social psychology, 90 (1), 60-77 PMID: 16448310
Dear Tal,
Like the blog. Just to note though, you appear to misunderstand what regression to the mean is. Its a phenomenon that occurs when you select based on high levels of depression. Even if nothing changes with their condition, their next score will probably be closer to the mean that the first.
Hi disgruntled; thanks for the comment. I’m not sure where you think the misunderstanding lies, though. What I said is that people tend to seek treatment for depression when they’re feeling particularly low; it therefore stands to reason that many people will get better irrespective of treatment simply because they’re regressing to the(ir own) mean. That seems to me to be exactly what you’re saying, no?
Hi,
Can’t help to point out Ehrlinger et al. (OBHDP, 2008), which addresses many of the issues raised by Kruger & Mueller, and Burson et al. It can be found by going to the Wikipedia site for the Dunning-Kruger Effect and looking at reference #2. In essence, Ehrlinger et al found:
1. That statistical regression to the mean accounted for only a smidgen of the DK effect. (The author of the current blog also does not address Kruger and Dunning, Study 3, which implicated metacognitive performance in the effect–and presented findings not predicted via a regression to the mean account.)
2. The effect arises in real world settings–such as exams, debate tournaments, and gun owners preparing for hunting season. That is, Burson et al. could modify the effect by introducing extreme conditions, but if we look at the types of tasks people face in their daily lives, the usual self-misestimates appear, with poor performers very much missing the mark.
3. The DK effect obtains even if respondents are promised up to $100 for accurate assessments.
The blog author is correct in describing what the original effect is–poor performers are overly confident relative to their actual performance. They are not more confident than high performers.
Couldn’t there also be an effect from the greater knowledge of the higher scorers and the universe they use for comparison? For instance, a chess whiz would be more likely to know accurately how his skills rated compared to those of Bobby Fischer than a man with normal chess skills would. If you are always comparing yourself to the very best, your self-assessment is always going to be more accurate with relation to them, but perhaps not so accurate with regard to the common run of men. Tasks that an expert considers easy might be more likely to be put into the “Oh, everyone can do THAT!” category by the expert than by the 99.5% of others who don’t have the first idea how to approach such a task.
Good point, Robert!
great post!
Hi Tal,
You still misunderstand regression to the mean. It’s a purely statistical phenomenon and has nothing to do with “natural history” or depressed people getting better or any actual change in the construct you’re trying to measure.
To work with your depression example: any time you try to measure depression, a person’s score will be made up of their actual depression and some error due to individual differences and randomness. If you measure the person again the very same day, the score will be different due to change in randomness and individual difference. So there will be some people whose first scores are outliers and seem to have exceptionally bad or exceptionally good mood, but don’t really. If you take the first scores and use them to select a sample of highly-depressed people for a study, you will scoop up all those low outliers. Their second scores will be much closer to the population mean and it’ll look like an improvement, but their mood HASN’T CHANGED.
What this hopefully makes clear is that regression to the mean is a phenomenon in repeated-measures experimental designs. That is, one where you take before-and-after measurements of your participants and compare them. If you’re only measured each thing once, as here, there can be no regression. I haven’t read the papers you cite so I don’t know how they make the case for regression to the mean, but your blog doesn’t make it.
Same thing the first poster said, but longer, hope it helps.
Hi Dr. Dunning,
Thanks for taking the time to reply. I was aware of the Ehrlinger et al paper, and had skimmed it prior to my original post, but in the interest of keeping things to a manageable length, I didn’t discuss it in the post. My apologies for that. I’ve now read it in detail, and here are my thoughts in response to the points you raise:
1. That statistical regression to the mean accounted for only a smidgen of the DK effect. (The author of the current blog also does not address Kruger and Dunning, Study 3, which implicated metacognitive performance in the effect–and presented findings not predicted via a regression to the mean account.)
The assumption in the Ehrlinger paper is that regression to the mean results from unreliability, in which case correcting for attenuation would provide better estimates of the “true” effect. But regression to the mean doesn’t just reflect reliability (or lack thereof); it can in fact (and generally will) take place in the presence of perfectly reliable measures. Take an extreme example: if all of the variance in people’s perceptions of their own performance reflected a single stable trait of self-perception (i.e., how good you think you generally are), self-perceptions would show extremely high test-retest and internal consistency reliability. Yet you would still get strong regression to the mean effects if you selected participants based on actual performance levels. The reason is simply that unless two variables are perfectly correlated, individuals who are extreme on one variable will generally not be extreme on the other. Again, this would be true even in the presence of two perfectly reliable variables. So I don’t think that the Ehrlinger analyses really demonstrate that regression to the mean isn’t a problem here.
With respect to the point about Study 3 in Kruger and Dunning, I have no trouble believing that result. As I noted in my post, I’m not suggesting that miscalibration between perception and actual performance is never due to metacognitive limitations; given your work and that of other people, I think that’s very plausible. The question is just how much of the variance under a range of circumstances reflects metacognitive limitations versus other more general explanations like regression to the mean, and in that sense, I find the evidence compelling that the latter account for the bulk of the effect.
2. The effect arises in real world settings–such as exams, debate tournaments, and gun owners preparing for hunting season. That is, Burson et al. could modify the effect by introducing extreme conditions, but if we look at the types of tasks people face in their daily lives, the usual self-misestimates appear, with poor performers very much missing the mark.
I think it’s very hard to determine which tasks are natural and which aren’t; it seems to me that the real world contains lots of instances of both the types of tasks you used in your studies, and the ones that Burson et al used. I don’t believe that, for instance, giving university undergraduates a multiple-choice trivia quiz on which the mean accuracy rate is 50% is ‘extreme’; situations like the ones Burson et al designed certainly do arise frequently in the real world! I’m willing to believe that there may be more situations in which people tend to do relatively well than in which they do very poorly, on average. But of course, even if that’s true, it still doesn’t mean the correct explanation for the resulting discrepancies between actual and perceived performance is metacognitive; Burson et al could be right about the source of the discrepancy but wrong about the distribution of difficulty levels in ordinary life (which I don’t think they make a statement about in any case).
3. The DK effect obtains even if respondents are promised up to $100 for accurate assessments.
I agree that this is a striking effect, but I don’t think it contradicts any of the alternative explanations I discussed. For instance, if (per Burson et al) a major source of information people use in determining their relative standing is their own subjective difficulty in performing a task, there’s no reason to think that paying subjects for performance is going to make them any more accurate. If I have little information to rely on other than how hard I found a task, why would offering me $100 make me do better? So again, I don’t see this as a problem for the accounts I’ve discussed.
Hi Matthew,
Thanks for the comment. But what I’m talking about is a purely statistical phenomenon. I’m saying that people’s levels of depression over time are stochastic; for any number of reasons, a person could be more depressed at time A than at time B. If you select your group of depressed people based on their scores at time A, they’re going to, on average, have more moderate scores at time B. Whether that reflects measurement unreliability or “true” change in mood is immaterial; from a measurement standpoint, it’s a purely statistical phenomenon.
And I don’t think it’s fair to characterize regression to the mean as only a problem for repeated measures. My sense is that it’s discussed more often in the context of relationships between different variables (for instance, here’s a nice paper providing several examples). If you select a group on the basis of variable A, and then measure variables B, C, and D, the means on those other variables will generally be less extreme. That’s a necessary feature of precisely the same statistical phenomenon, and will happen (on average) any time the correlation coefficient between two variables is less than one.
Interesting. One example of DK that comes to mind is driving ability: it seems to me that poor and mediocre drivers perceive themselves as much more competent than they actually are. My guess is that, like the children of Lake Wobegone, nearly every driver rates himself as above average.
It also seems to me that the current denizen of the White House perceives his performance (“a solid B+”) as somewhat higher than actual results would suggest.
Hi Robert,
Thanks for the comment. This sounds similar to a point Krajc and Ormann made recently. They pointed out that the inferential problem faced by people at the low end of the samples Dunning, Kruger et al used may be more difficult than the problem faced by those at the high end. The issue being that Cornell undergraduates tend to be drawn from the positive end of the distribution, and probably would have had limited prior experience being amongst other people of their own ability. In other words, if you’re used to be being at the upper end of the distribution relative to the general population, and then you’re dropped into another pool of much higher-performing people, it shouldn’t be surprising if it looks like you’re miscalibrated. Whereas people at the high end of the sample don’t have that problem, because if they perform well relative to a highly selective sample, they obviously would also perform well relative to a more general sample.
Hi Tal,
Thanks for the link, I see your point now and I’ve learned something about regression to the mean.
I do think that your last reply viz measurements as stochastic variables changing for any number of immaterial reasons is basically the position of the first commenter and me, but quite different from the position in your blog post where you devote a whole par to explaining regression to the mean for depression in terms of natural history. It’s the attempt to identify the immaterial and unidentifiable that caught our attention. And both the examples you give in the post are repeated measures. Clearly you understand the phenomenon better than I do, but it doesn’t come through in your post for those reasons.
Hi Matthew,
That’s fair; you’re right, I was a bit careless in my example. I wasn’t really making any deep point about depression per se, but simply pointing out that changes in behavior that often get interpreted substantively by researchers may not reflect anything important about the course of depression itself, but are simply a statistical artifact. But I concede that this is viewpoint dependent to some extent; if you’re someone who studies clinical depression (which I’m not), you might well want to separately consider veridical changes in people’s mood from regression to the mean induced by measurement error.
> 1. That statistical regression to the mean accounted for only a smidgen of the DK effect.
The top quartile from the 1999 paper, at least, looks dominated by “regression to the mean” to the point where it even overcomes the effect of positive illusions. Much more than what I would call a smidgen, at least for the 1999 paper! Or is there a better alternative explanation?
The DK effect obtains even if respondents are promised up to $100 for accurate assessments.
The question is whether that assessment task demand more than trivial cognitive ability. In that case, monetary rewards will do no good, as discussed in this research presentation.
Do you think that this effect is relevant for older adult perceptions of memory deficits. The worse performers feel that they are OK versus those with memory function that is actually above average, worry more deeply about performance issues?
Thanks for the post, and the great commentaries. I’m immediately reminded of the recently reported fact that American students have the lowest math scores in all areas except confidence where they outscore all other nations. In this case, I’m afraid, the least competent seems to have the highest assessment of themselves. I take this as very bad news.
Bertrand Russell said…
“The biggest cause of trouble in the world today is that the stupid people are so sure about things and the intelligent folks are so full of doubts.”
Ecclesiastes 1:9
New King James Version (NKJV)
9 That which has been is what will be,
That which is done is what will be done,
And there is nothing new under the sun.
I’m a big fan of Russell’s, David, but in this case that’s actually not what the data show. The Dunning-Kruger effect is that incompetent people are wildly overconfident whereas competent folks are much better calibrated. But, Russell’s comment notwithstanding, the competent people still think they’re better than the incompetent people do. And in fact, there’s some of the other evidence I mentioned above showing that when the task is very difficult, you can get the effect to flip entirely (i.e., so that less competent people are now more accurate when judging their own incompetence).
Robin Hanson made a similar argument a while back, but without those graphs:
http://www.overcomingbias.com/2011/03/the-unskilled-are-aware.html
The subjective ‘how did I do?’ feeling is absolute, but being plotted against a relative measure. Even if you’re exactly 50% percentile, scoring 8/10 feels better than scoring 4/10. Based on the above graph, I would conclude that the subjective measure is pretty accurate in an absolute sense.
This is consistent with the second graph. As a bonus, if that kink at the bottom end isn’t an artifact, it’s also still consistent with DK effect.
This reminds me of the time when my kids were small, and the mother and I were busy buckling them into the car seats for a trip. Her mother said, “You people these days! When I had little kids we just put them in the back of the station wagon and drove off. Look, now! They are all fine!” To which I replied, “That’s because all the dead kids can’t tell their side of the story.”
If I may quote Charles Darwin, The Descent of Man
“Ignorance more frequently begets confidence than does knowledge: it is those who know little, not those who know much, who so positively assert that this or that problem will never be solved by science.â€
I am sure I don’t know what I just read
I found a solution to this play in the mind. I realised this character I was assuming I was was actually a result of outside influences. I had a dig in my past. It seems school left a neediness for a false me to be created to take the brunt of the world. Like a early brain development reflex.
I observed what was arising in me for desire and thought without reacting to it for a while. Cut myself off from outside influences and media. Especially entertainment and news.
Imagine a person studying a painting. After years of research, he knows:
1. All the colors that were used in the painting.
2. The type and design of the brushes used.
3. The origin of the frame, the age of the frame.
4. The origin of the canvass, the age of the canvass.
5. Etc etc
Now, here is my question:
What does he know about the painter after years of study?
Now, imagine a scientist studying the universe.
Into which category will he fall?
If he is really sharp, he might know when to recognize the false equivalency fallacy
He might know how to spell “canvas.”
Thank you!, John, for supporting my argument, and yes, you are correct, he will (only) know how to spell the names of all the articles, tools, implements he used during his life.
Once again, John, thank you for canvassing on my behalf.
I used to be modest. Then, I had people take advantage of me enough times. I had a 1440 SAT. One boss mistook my modesty for incompetance. I’m like, “Dude! I have a 1440 SAT. I’m just modest.” If you are humble and correct people for not comprehending the vastness of your intelligence. You can big a bigger person and let the pathetic person think you are stupid, but ouch. Oh hell no, not when it has consequences. You gotta get in their face and never be modest or they’ll mistake you for a loser.
Very interesting post. Another way it seems to be misinterpreted is that it shows unintelligent people don’t know they are unintelligent/over-estimate their own intelligence (again because they don’t possess the mental tools to realise their lack of knowledge). But this study looked at competence rather than IQ (whilst you could make the argument logic is linked to IQ, I doubt many would argue they are synonymous). Do you think IQ tests could be used in the same way to judge and compare intelligence (as they did with competence in the original study)? Are there any studies that look at IQ in this way?